指南
下载权重
下载权重
在 WebUI 上复制权重ID:
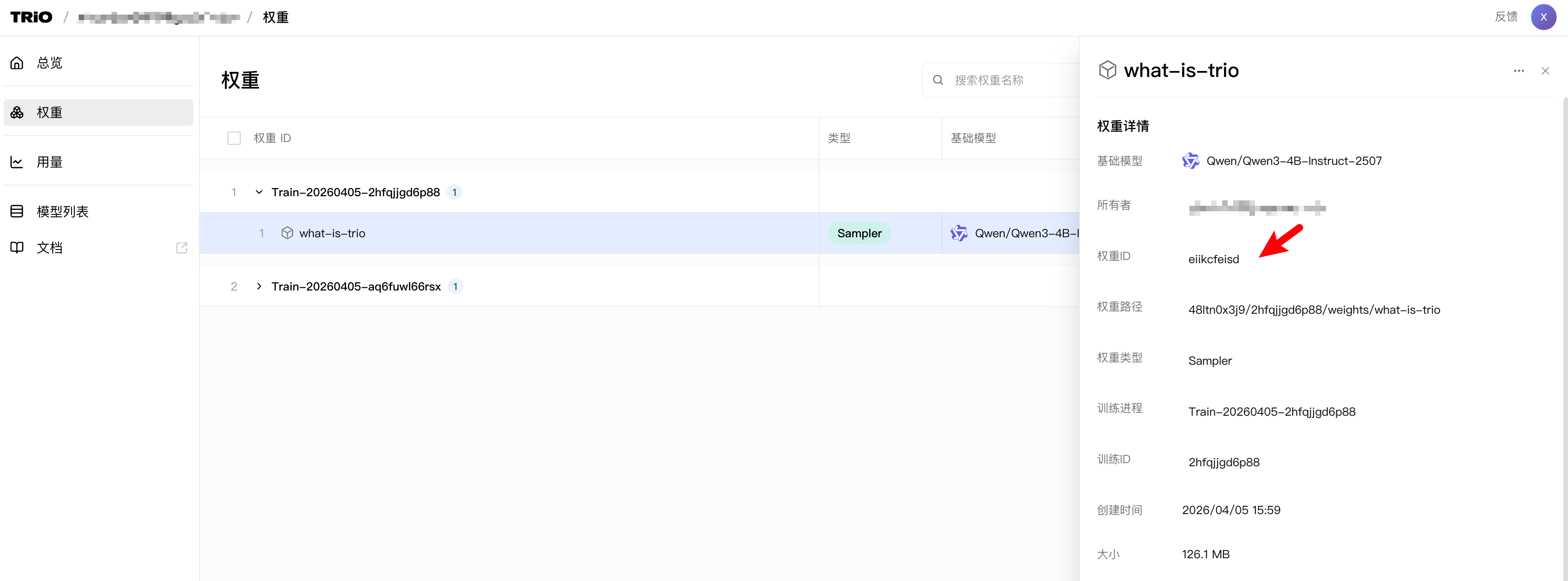
将权重ID粘贴到下面代码的checkpoint_id处,执行脚本即可将Lora权重下载到本地。
import pytrio as trio
import requests
import os
client = trio.ServiceClient()
rest_client = client.create_rest_client()
checkpoint_id = "YOUR CHECKPOINT ID"
res = rest_client.get_checkpoint_archive_url(checkpoint_id).result()
print("Got the model download link::", res)
download_url = res.url
save_filename = f"{checkpoint_id}.zip"
with requests.get(download_url, stream=True) as response:
response.raise_for_status()
with open(save_filename, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"File download complete! Save path: {os.path.abspath(save_filename)}")下载得到的是一个 .zip 压缩包,解压后包含一个 LoRA adapter(基于 PEFT 库格式),而不是完整的模型权重。目录结构如下:
checkpoint/
├── adapter_config.json # LoRA 配置(rank、alpha、目标层等)
├── adapter_model.safetensors # LoRA adapter 权重(体积远小于完整模型)
└── generation_config.json # 生成参数(temperature、top_p 等)由于只包含 adapter,部署时需要配合对应的 base model(如 Qwen/Qwen3.5-4B)一起使用。
部署模型
下载 adapter 后,有以下两种方式在本地部署并使用训练后的模型。
这里以Qwen/Qwen3.5-4B为例,首先需要下载 base model。
国内网络推荐用 ModelScope:
pip install modelscope
python -c "from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3.5-4B', local_dir='./base_model')"或使用 HuggingFace(需要能访问 HuggingFace):
pip install huggingface_hub
huggingface-cli download Qwen/Qwen3.5-4B --local-dir ./base_model方法一:Transformers + PEFT
最简单的方式,无需合并权重,适合快速验证训练效果。
pip install transformers peft accelerate torchimport torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
BASE_MODEL_PATH = "./base_model"
ADAPTER_PATH = "./checkpoint" # checkpoint目录下是zip解压后的文件
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL_PATH,
dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
# 挂载 LoRA adapter
model = PeftModel.from_pretrained(model, ADAPTER_PATH)
model.eval()
messages = [{"role": "user", "content": "你好,请介绍一下你自己。"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(**inputs, max_new_tokens=512, temperature=0.7, top_p=0.8, do_sample=True)
new_ids = output_ids[0][inputs["input_ids"].shape[1]:]
print(tokenizer.decode(new_ids, skip_special_tokens=True))方法二:合并 LoRA 到 Base Model
将 adapter 权重合并进 base model,得到一个独立的完整模型,后续部署更灵活。
# merge_lora.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
BASE_MODEL_PATH = "./base_model"
ADAPTER_PATH = "./checkpoint"
MERGED_PATH = "./merged_model"
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL_PATH,
dtype=torch.bfloat16,
device_map="cpu", # 合并时用 CPU 节省显存
trust_remote_code=True,
)
model = PeftModel.from_pretrained(model, ADAPTER_PATH)
model = model.merge_and_unload()
model.save_pretrained(MERGED_PATH, safe_serialization=True)
tokenizer.save_pretrained(MERGED_PATH)
print("Merge!")python merge_lora.py合并完成后,merged_model/ 是一个标准的 HuggingFace 模型,可用于任意 HuggingFace 模型支持的部署方式,比如 vLLM、SGLang、Ollama 等。